




Control • Predict • Analyze
Artificial Intelligence and Machine Learning

Research
 Brain-Computer Interfaces at CSU (1994-) Brain-computer interfaces (BCIs) are hardware and software systems that sample electroencephalogram (EEG) signals from electrodes placed on the scalp and extract patterns from EEG that indicate the mental activity being performed by the person. The long-term goal of this line of research is a new mode of communication for victims of diseases and injuries resulting in the loss of voluntary muscle control, such as amyotrophic lateral sclerosis (ALS), high-level spinal cord injuries or severe cerebral palsy. The autonomic and intellectual functions of such subjects continue to be active.This can result in a locked-in syndrome in which a person is unable to communicate to the outside world.
Brain-Computer Interfaces at CSU (1994-) Brain-computer interfaces (BCIs) are hardware and software systems that sample electroencephalogram (EEG) signals from electrodes placed on the scalp and extract patterns from EEG that indicate the mental activity being performed by the person. The long-term goal of this line of research is a new mode of communication for victims of diseases and injuries resulting in the loss of voluntary muscle control, such as amyotrophic lateral sclerosis (ALS), high-level spinal cord injuries or severe cerebral palsy. The autonomic and intellectual functions of such subjects continue to be active.This can result in a locked-in syndrome in which a person is unable to communicate to the outside world.
The interpretation of information contained in EEG may lead to a new mode of communication with which subjects can communicate with their care givers or directly control devices such as televisions, wheel chairs, speech synthesizers and computers.
The main objectives of this project are to develop open-source software for on-line EEG analysis and brain-computer interfaces; compare signal quality and BCI performance of various EEG systems in users’ homes; develop new algorithms for identifying cognitive components in spontaneous EEG related to mental tasks as a basis for new BCI protocols; improve BCI reliability by allowing users to adapt through real-time feedback and by adapting the BCI algorithms using error-related EEG components; and experiment with interaction of two people using BCIs. Results are evaluated by the accuracy of EEG classification, the speed with which the classification can be performed, and the expense of the EEG system and of its maintenance and extendibility.
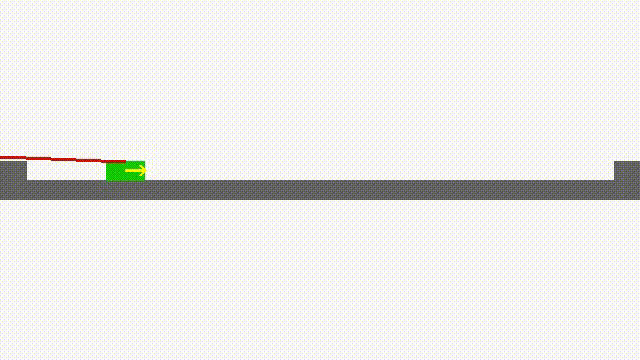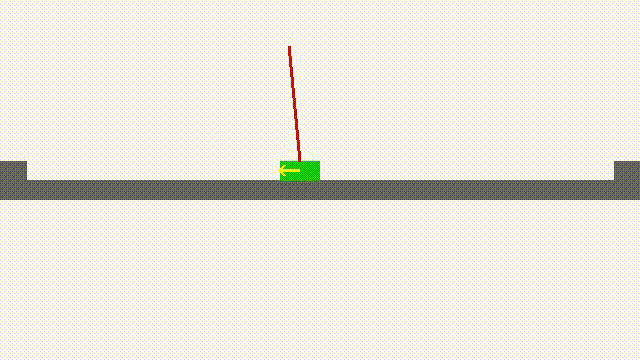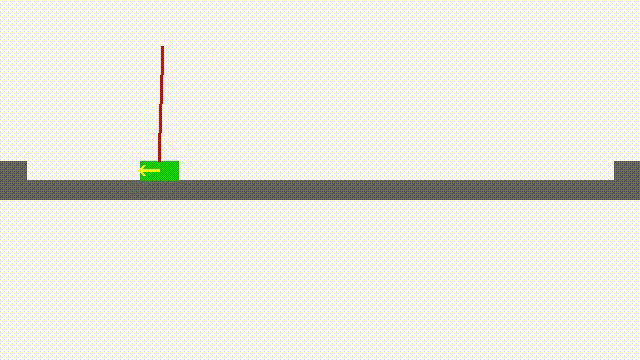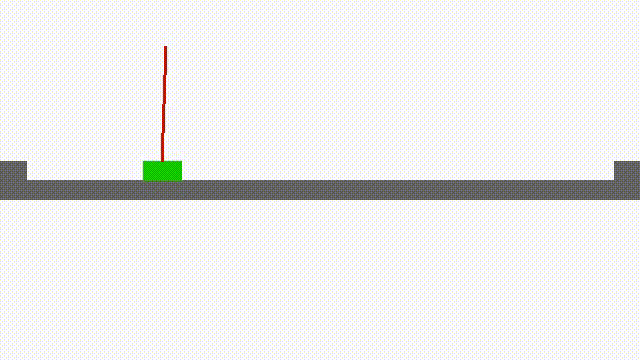 Faster Reinforcement Learning After Pretraining or with Simultaneous Supervised Learning of Deep Networks (2015-): Reinforcement learning problems are ones for which correct actions must be learned by experience. Performance feedback is provided by an evaluative feedback, or reinforcement, that is based on the behavior of a system being controlled by the actions. Correct actions are not known before hand. Reinforcement learning algorithms have a reputation of being slow, partly because it can take a lot of interactions before performance is optimized. Another reason they are thought to be slow is that two kinds of problems must be solved: good actions must be discovered, and these actions must be associated with the state of the system. It is this second problem that supervised learning algorithms deal with. Deep neural networks are continuing to surpass state-of-the-art supervised algorithms in many domains. In this project, we are investigating the use of deep neural networks in a reinforcement learning framework. Deepmind, and others, have had considerable success with this approach. However, adding the long training times required for deep nets to the large number of interactions required for reinforcement learning problems can be problematic. We are investigating novel ways of pretraining the hidden layers of neural networks to learn representations that are useful in predicting next state from current state and action. Such information is available before any goal-oriented reinforcement values are introduced. We have found that for the pole-balancing problem a large reduction in reinforcement learning time resulting from pretraining deep Q-networks in this way.
Faster Reinforcement Learning After Pretraining or with Simultaneous Supervised Learning of Deep Networks (2015-): Reinforcement learning problems are ones for which correct actions must be learned by experience. Performance feedback is provided by an evaluative feedback, or reinforcement, that is based on the behavior of a system being controlled by the actions. Correct actions are not known before hand. Reinforcement learning algorithms have a reputation of being slow, partly because it can take a lot of interactions before performance is optimized. Another reason they are thought to be slow is that two kinds of problems must be solved: good actions must be discovered, and these actions must be associated with the state of the system. It is this second problem that supervised learning algorithms deal with. Deep neural networks are continuing to surpass state-of-the-art supervised algorithms in many domains. In this project, we are investigating the use of deep neural networks in a reinforcement learning framework. Deepmind, and others, have had considerable success with this approach. However, adding the long training times required for deep nets to the large number of interactions required for reinforcement learning problems can be problematic. We are investigating novel ways of pretraining the hidden layers of neural networks to learn representations that are useful in predicting next state from current state and action. Such information is available before any goal-oriented reinforcement values are introduced. We have found that for the pole-balancing problem a large reduction in reinforcement learning time resulting from pretraining deep Q-networks in this way.
 Climate Informatics (2015-): Atmospheric data sets often consist of multiple time series with unknown, complex interrelationships. In this project we seek to explore what kind of interrelationships can be discovered in climate data by applying the framework of artificial neural networks. As a first application we look at establishing relationships between top of atmosphere radiative flux and air/surface temperatures. This is an important application, since a thorough understanding of those relationships is essential for understanding the effect of CO2-induced warming on the Earth’s energy balance and future climate.
Climate Informatics (2015-): Atmospheric data sets often consist of multiple time series with unknown, complex interrelationships. In this project we seek to explore what kind of interrelationships can be discovered in climate data by applying the framework of artificial neural networks. As a first application we look at establishing relationships between top of atmosphere radiative flux and air/surface temperatures. This is an important application, since a thorough understanding of those relationships is essential for understanding the effect of CO2-induced warming on the Earth’s energy balance and future climate.
 Protein Aggregation Propensity (2013-): Numerous proteins contain domains that are enriched in glutamine and asparagine residues, and aggregation of some of these proteins has been linked to both prion formation in yeast and a number of human diseases. Unfortunately, predicting whether a given glutamine/asparagine-rich protein will aggregate has proven difficult. Here we describe a recently developed algorithm designed to predict the aggregation propensity of glutamine/asparagine-rich proteins.
Protein Aggregation Propensity (2013-): Numerous proteins contain domains that are enriched in glutamine and asparagine residues, and aggregation of some of these proteins has been linked to both prion formation in yeast and a number of human diseases. Unfortunately, predicting whether a given glutamine/asparagine-rich protein will aggregate has proven difficult. Here we describe a recently developed algorithm designed to predict the aggregation propensity of glutamine/asparagine-rich proteins.

Techniques
Over decades of experience developing novel neural network training algorithms and implementations, the evolution of our software base has been guided by the wide variety of applications we have dealt with and by its use in numerous undergraduate and graduate courses at Colorado State University in machine learning. The structure of our software is designed for quick specialization to any application.
Advantages of our software include
- Neural network computations based on very efficient Python numpy package
- Data and computations of a neural network are fully transparent and easily accessible for analysis and interpretation to explain what has been learned by the network
- Use of efficient optimization algorithm that combines conjugate gradient and approximate second order computations
- full specification of gradient computation rather than relying on slower automatic differentiation methods
- successful tests in numerous applications
- simple to run on CPUs or GPUs

It is used through a simple API. For example, a deep neural network with 100 input components, 10 hidden layers each with 100 units, and 20 output units, is constructed by the python statement
nnet = NeuralNetwork((10, [100]*10, 20))
and trained by
nnet.train((X,T,100))
with X being a matrix with hundreds or thousands of rows with each row containing a 10-dimensional sample, and T is a similar matrix of desired outputs for each sample. Alternatively, the network can be trained on a GPU by constructing it with
nnet = NeuralNetwork((10, [100]*10, 20, useGPU=True))
A major limitation of current approaches to deep learning applications is the narrow focus on the accuracy with which applied neural networks model or predict the given data. Often an increase of a few percent in classification accuracy is heralded as a great achievement. However, in most investigations, this is just a preliminary step. You, the provider of the data, are probably more curious about the relationships inherent among the measurements. You want to know what patterns exist in the data from which you can gain a better understanding of the underlying processes that generated the data.
This is the focus of Pattern Exploration, LLC. Our objective in any collaboration is to explore for the patterns hidden in the data. We accomplish this through the development of custom analyses and visualizations of what deep learning reveals in ways that are immediately understandable by you, the application experts.

Much of the research in deep learning had been directed at reducing the training time. We understand that it is as, or more, important to the application experts to reduce computation time when using a trained network to infer correct outputs for new data. To this end we have developed a cascade structure that very quickly produces an approximately correct output that is incrementally refined as time allows.
For example, in a common benchmark problem of classifying hand-drawn digits, the confidence of classifying an image as a particular digit grows as computation includes more layers. For some images, the correct digit is confidently identified very fast with just one or two layers being computed. For other more difficult to classify images, more layers are required.
Starting in the 1980’s, we have continued to refine our algorithms for training deep neural networks as approximations of state-action value functions to enable efficient reinforcement learning. In a real-world application, efficiency is measured in terms of the number of interactions required with the system or environment to be controlled.
Our approach to reinforcement learning has always been focused on minimizing the number of interactions required. In recent work, we developed a technique by which a deep network is first trained to model passively-observed measurements of the system, before any actual control is attempted. This results in the formation of a rich representation of the system that is very likely to reduce the number of interactions required to learn to control the system. We demonstrated this on a pole swing-up and balance problem.

Applications

Starting with the best engineered feedback controllers, deep networks operate in parallel with the engineered controllers and are trained to modify the control actions in situations when the controllers do not provide optimal performance. Such situations arise from inaccuracies in modeling and derivation of controllers and from changes in the system being controlled over time. In this application, the synthesis of the controller and the deep network trained with reinforcement learning are is guided by robust control theory, resulting in proofs of static and dynamic stability, even while being trained. This work has resulted in the following patents:
- Combined proportional plus integral (PI) and neural network (NN) controller. Patent Number US7117045B2.
- Control system and technique employing reinforcement learning having stability and learning phases. Patent Number US6665651B2
and publications
- Stable Adaptive Neural Control of Partially Observable Dynamic Systems. J. Knight and C. Anderson. In Reinforcement Learning and Approximate Dynamic Programming for Feedback Control, ed. by F. Lewis and D. Liu, John Wiley and Sons, Inc., Chapter 2, pp. 31-51, 2013.
- Anderson C.W., Young P.M., Buehner M.R., Knight J.N., Bush K.A., and Hittle D.C., Robust Reinforcement Learning Control using Integral Quadratic Constraints for Recurrent Neural Networks, IEEE Transactions on Neural Networks: Special Issue on Neural Networks for Feedback Control Systems, vol. 18, no. 4, pp. 993-1002, July 2007.

The control of wind turbines is complicated by variations in wind and inaccuracies in models of mechanical and electrical dynamics of the wind turbine. We developed a new approach by combining existing controllers with a reinforcement learning agent. Energy generated by a wind turbine was increased by 6% in a simulation study.
On-Line Optimization of Wind Turbine Control using Reinforcement Learning, C. Anderson. Poster at the 2nd Annual CREW Symposium at Colorado School of Mines, Golden, Colorado, 2010.

In constructing three-dimensional models of animal organs and tissue from cross-section images, Visible Productions of Fort Collins, Colorado, would hire anatomy students to manually trace the boundaries on each slice. We trained a neural network to duplicate the decisions the students would make as they traced a boundary. After training, the neural network would continue drawing a boundary started by a student after drawing just a few pixels.

In 1995, the FAA and NASA formed the AGATE consortium to develop the “highway in the sky” concept by which pilots and more easily learn to fly single engine aircraft in nearly all weather conditions. We developed a gated network of neural network “expert" controllers, each automatically tuned to a different aspect of flying, that models a pilot's behavior. Since each “expert” module represents a different piloting skill,the set of skills acquired by the student pilot can be identified, and further training can be directed to the learning of skills that are missing or insufficiently learned. This work is summarized in:
- Anderson, Draper, and Peterson (2000) Behavorial Cloning of Student Pilots with Modular Neural Networks, in Proceedings of the International Conference on Machine Learning, Stanford University, June 29-July 2, 2000.